I Agree with Nate Silver, the Pollsters Are Herding
Photo by Quinnnnnby, CC BY-SA 4.0
I looked at every single presidential election poll from North Carolina, Georgia, and Michigan in FiveThirtyEight‘s database since August 28th, and I think it is clear that something weird is going on with the polls. Every swing state has the same dynamic, where the vast majority of polls fall within an extremely narrow range around a tied race. I am not suggesting these races are not dead even, just that if they are, we should see far more variability in poll results than we are. It may be a true tossup election, but the story the polls are telling simply does not make sense to how sampling works. I am no Nate Silver fanboy, I have already proven at Splinter that I am loath to hand it to him, but I think his allegation here is correct.
There are too many polls in the swing states that show the race exactly Harris +1, TIE, Trump +1. Should be more variance than that. Everyone’s herding (or everyone but NYT/Siena).
— Nate Silver (@NateSilver538) October 29, 2024
It’s such a simple and obvious notion that ChatGPT can write accurate R code demonstrating the disconnect between expectations and reality. I told ChatGPT to write code assuming a political race is exactly even, and to simulate a sample of ten thousand polls with a random selection of a thousand respondents in each, and then to plot the distribution of polls along a histogram. This is what a natural sampling variation of a dead polling heat should produce (the magnitude of polling returns is less important to note than the overall shape this chart creates: a bell-curved normal distribution).
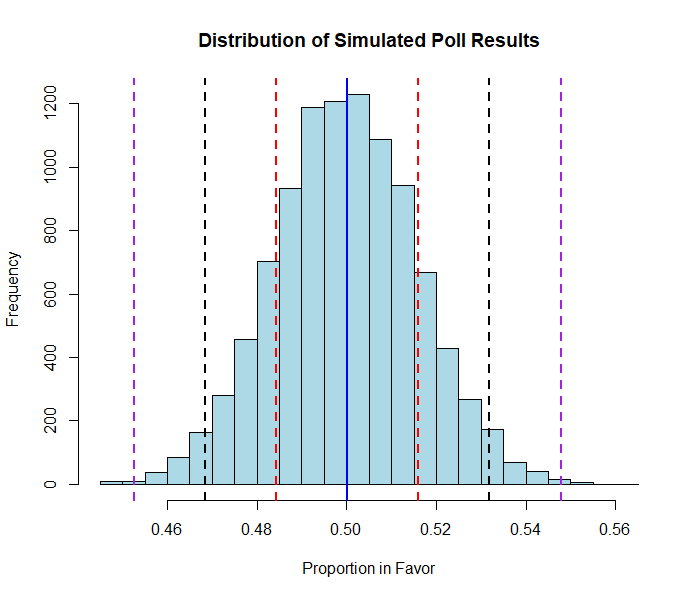
The vertical bars I added are for the 68-95-99.7 rule, which is an ironclad law that a little over two-thirds of all results in a normal distribution will fall within one standard deviation of the mean (the red bars), 95 percent will fall within two standard deviations of the mean (the black bars), and 99.7 percent will fall within three standard deviations of the mean (the purple bars). While it would take a lot more work than I am willing to do for this blog to calculate a true mean and standard deviation from these three hundred-plus polls from all three states I looked at, they cumulatively suggest a 50-50 race, which would place the mean at zero. While the regular three-point margin of error pollsters use for a sample of roughly one thousand will likely slightly overstate the standard deviation in their samples, it is still an accurate ballpark figure to use to approximate the standard deviation in their polling. It is not unreasonable to assume that roughly two-thirds of polls in every 50-50 state should fall between Trump +3 and Harris +3.
But that’s not the case. In both Michigan and Georgia, 84 percent of polls since August 28th peg either candidate up three points or less, while in North Carolina, a whopping 95 percent of polls have the race between Trump +3 and Harris +3. Joshua Clinton, Professor of Political Science at Vanderbilt University, posted this chart yesterday with the range of actual Pennsylvania polling imposed on to his more scientific simulated sampling exercise of what I had ChatGPT give me above, highlighted in the lighter shade.
Hmm…. pic.twitter.com/akgzTWHn9h
— Joshua Clinton (@joshclinton) October 30, 2024
The problem is that polls are not creating a normal distribution like simulated sampling exercises do, which is what the polls are implying they should be doing with all these dead-even races. I guess you could zoom way in and argue that they are producing something like a normal distribution, just all tightly packed in between zero and three points, but even in a true 50-50 race, you’ll still get some consistent variability in polls suggesting one candidate is up five points or more instead of just a token outlier or two. The charge of “herding” is that the pollsters are massaging their polls in some way towards an even result or even removing data they believe to be outliers, artificially pushing every single poll more towards the middle.
Here is a remarkable demonstration of how much a pollster’s choices affect the results. @joshclinton took a single poll and depending on the weighting scheme, he could change the Harris-Trump margin by as much as *8 points*.https://t.co/94s63GXncB
— John Sides (@johnmsides) October 28, 2024
So why would pollsters herd? Simple human nature, really. They operate in a hyper-competitive environment where ratings from sites like FiveThirtyEight really matter to their business, so if one pollster is going out on a limb relative to everyone else and they are wrong, they will be regarded as less credible going forward. If they are bunched up in the middle alongside a hundred other pollsters and they all are wrong, then they are all safe. Hence, herding.
As Conor Sen of Bloomberg noted, this has echoes of the financial industry, and he wonders “if the future of polling is going to be like Wall Street economists forecasting econ numbers, where you’re just trying to beat the consensus number by a bit rather than get the number right.”
So what does this mean for the election? There’s no reason to believe that it isn’t very close, because early voting backs that notion up, but it also means that the polls have so heavily concentrated around zero that a polling miss within the margin of error could still lead to either candidate winning every single swing state. Election night could feature a huge electoral college blowout while statistically, the avalanche of pollsters saying it was a dead heat were still correct.
It also could mean they are downplaying Democratic votes as suggested by the historically predictive Washington open primary, whose results implied a D+3 environment, while VoteHub.us’s 28-day rolling average of highly rated pollsters pegs it currently at D+1.7, with Trump slated to win. The enthusiasm gap between the parties also suggests that polls could be slightly downplaying Democratic strength, as could the early vote gender gap in the six states the track that data.
They also could be under-selling a Republican landslide due to the longtime inability to predict what Trump’s main target, low propensity voters, will do on election day. Pollsters have essentially ensured that so long as neither candidate wins a swing state and the national vote by more than three points, they can say they were right no matter what. If this is happening and it is the direction that polling is headed, then the critics wrongly asserting that polling is a useless exercise will finally be right for once.